LessWrong (Curated & Popular)
Audio narrations of LessWrong posts. Includes all curated posts and all posts with 125+ karma.
If you'd like more, subscribe to the “Lesswrong (30+ karma)” feed.
LessWrong (Curated & Popular)
"Can activation verbalizers surface an internal chain of thought?" by oakhu, ryan_greenblatt
Use Left/Right to seek, Home/End to jump to start or end. Hold shift to jump forward or backward.
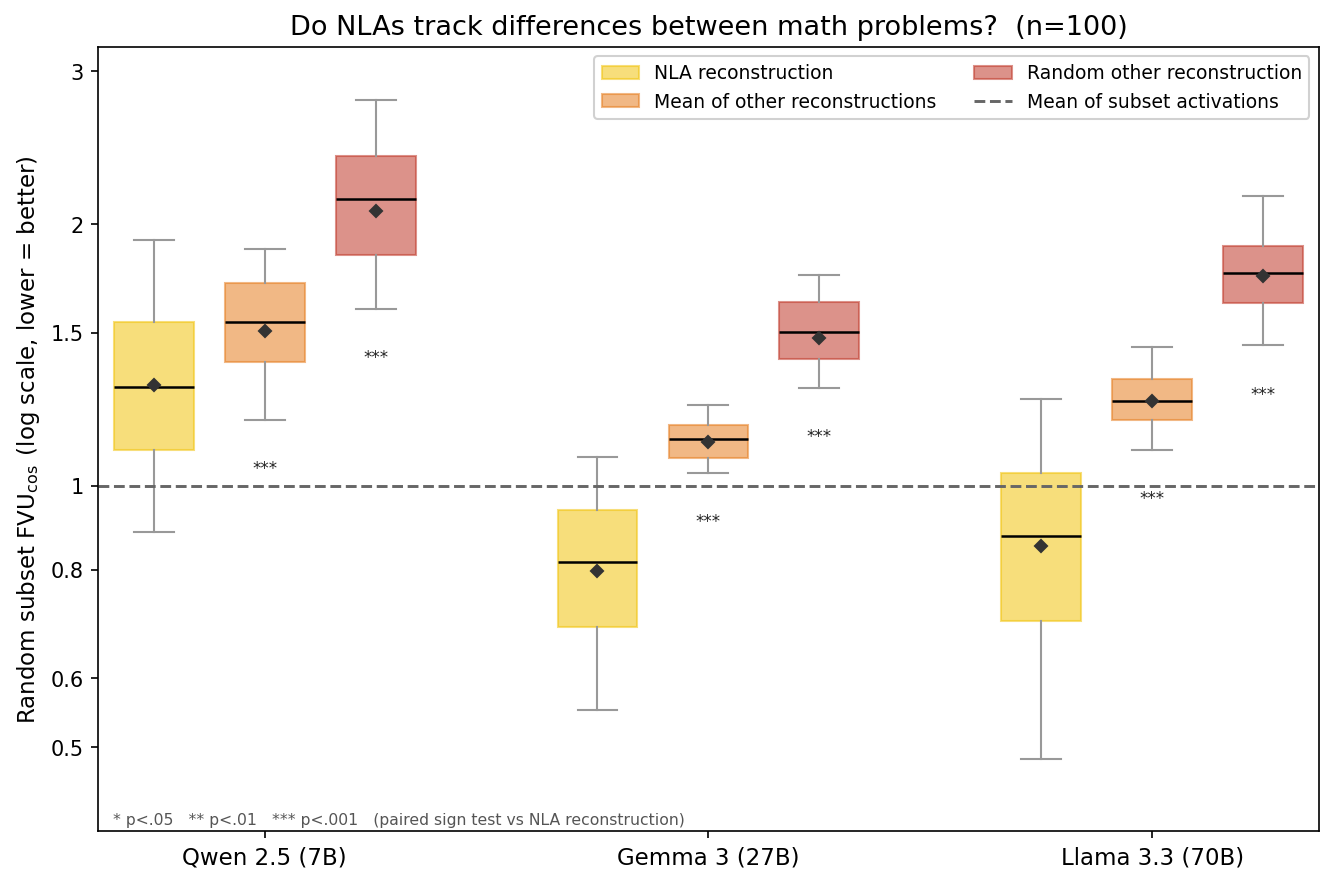
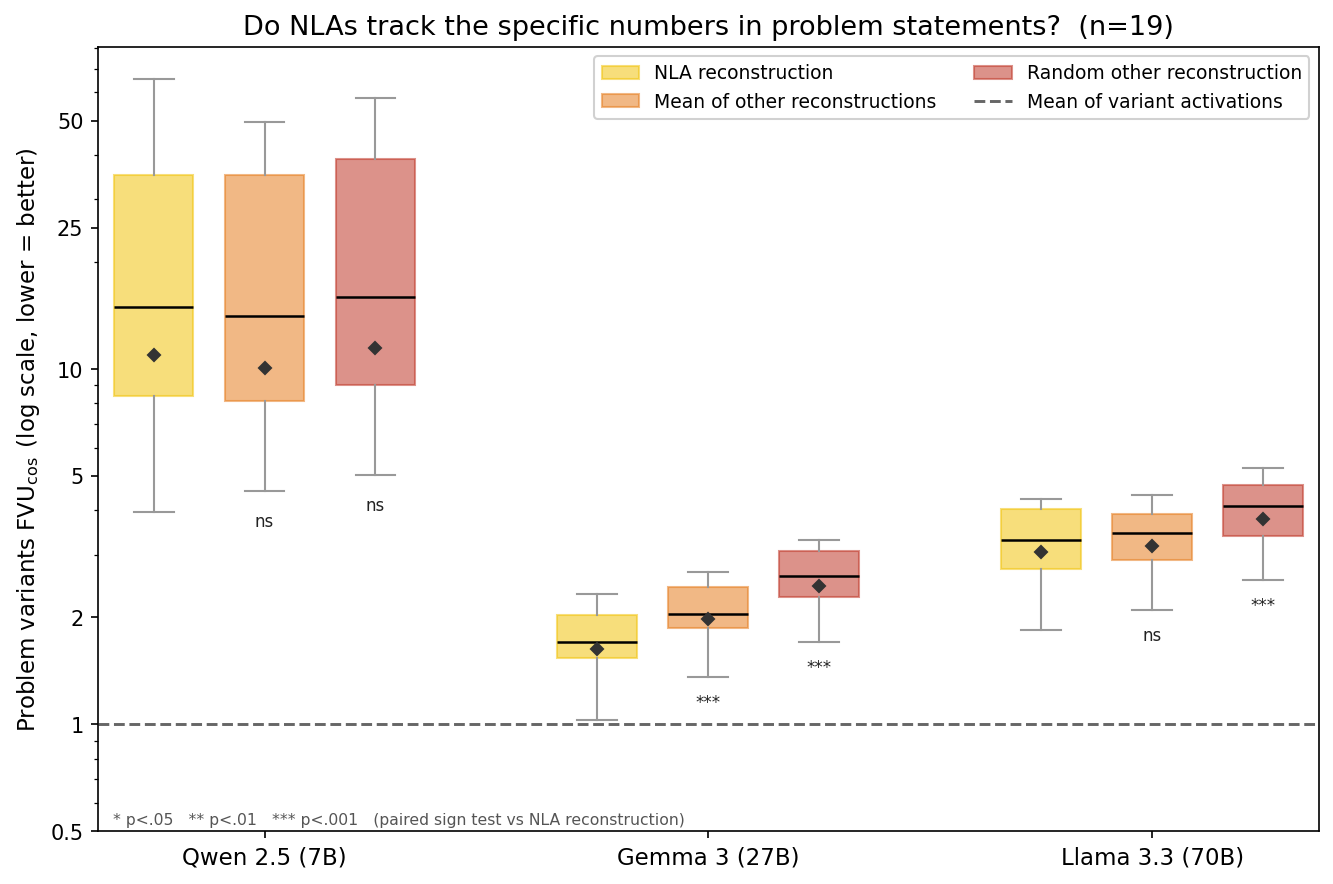
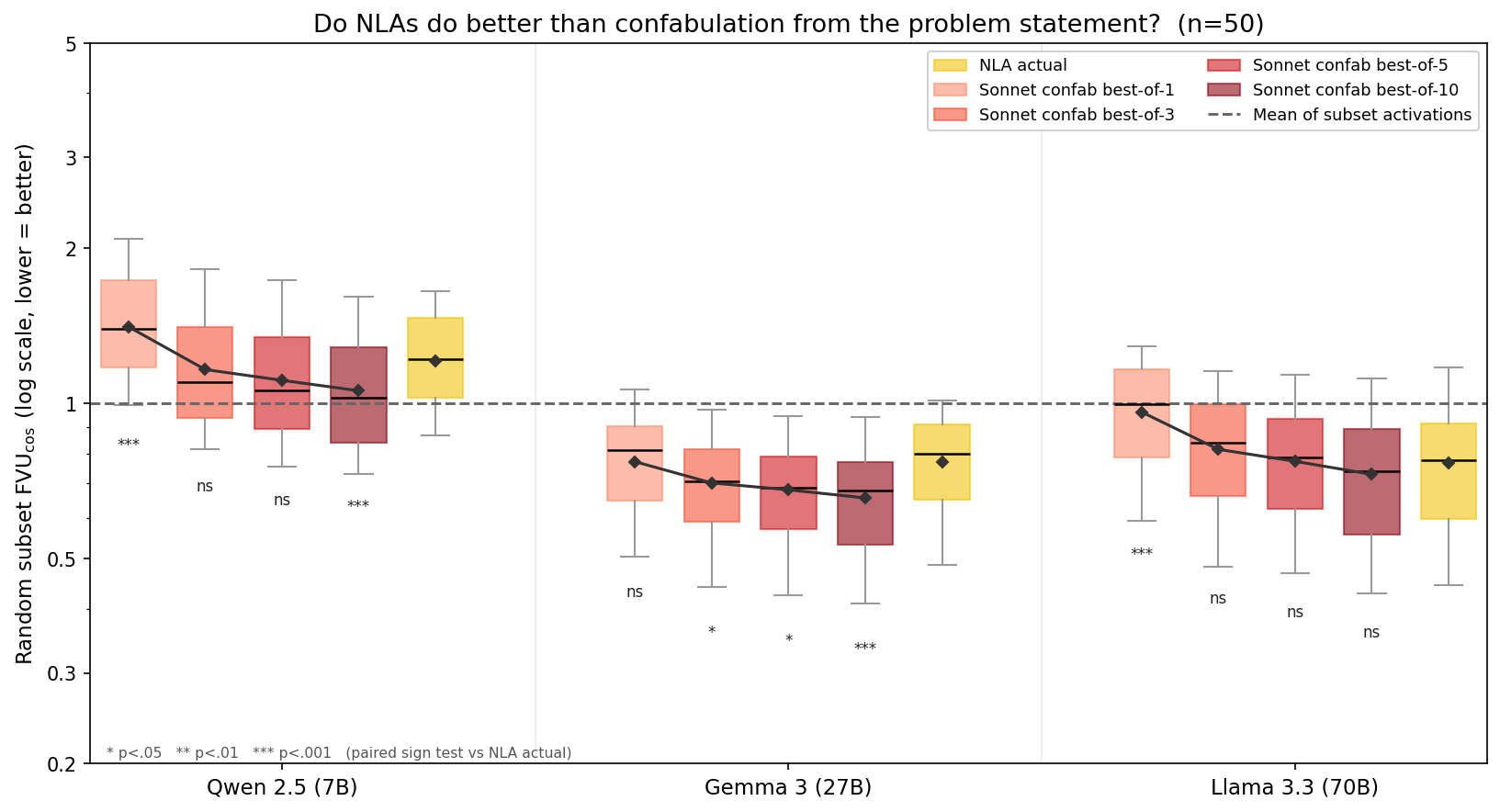
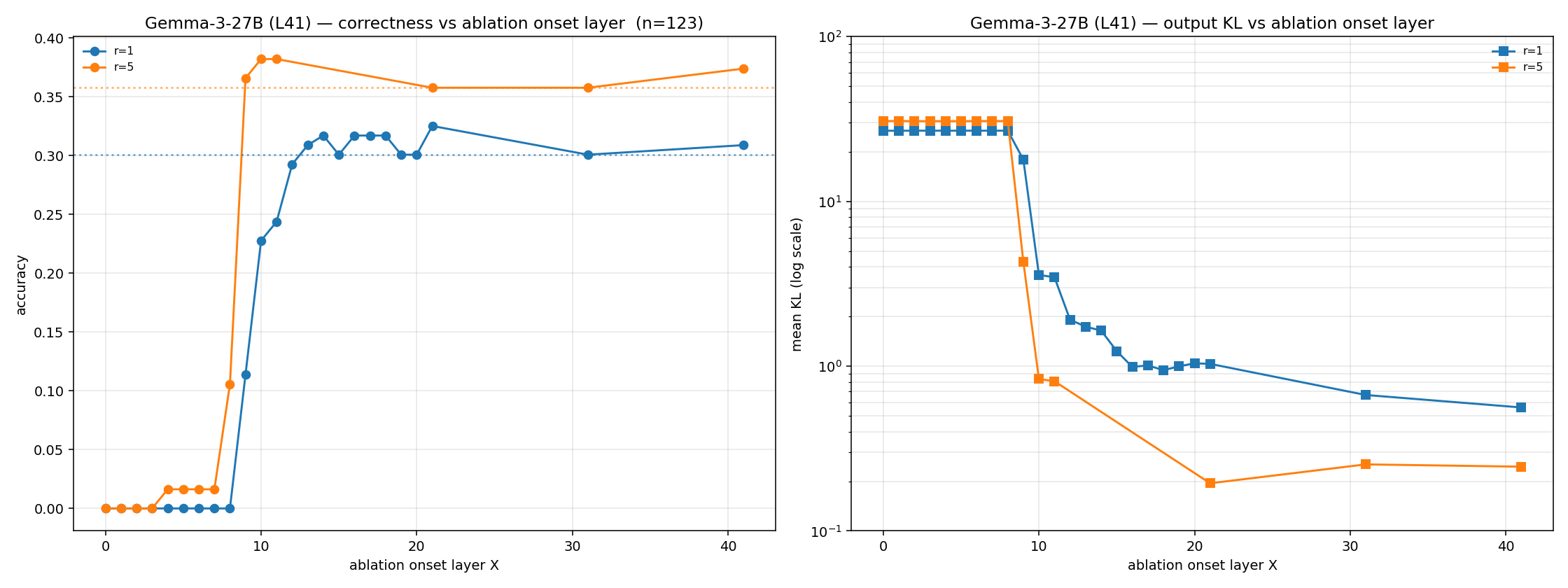
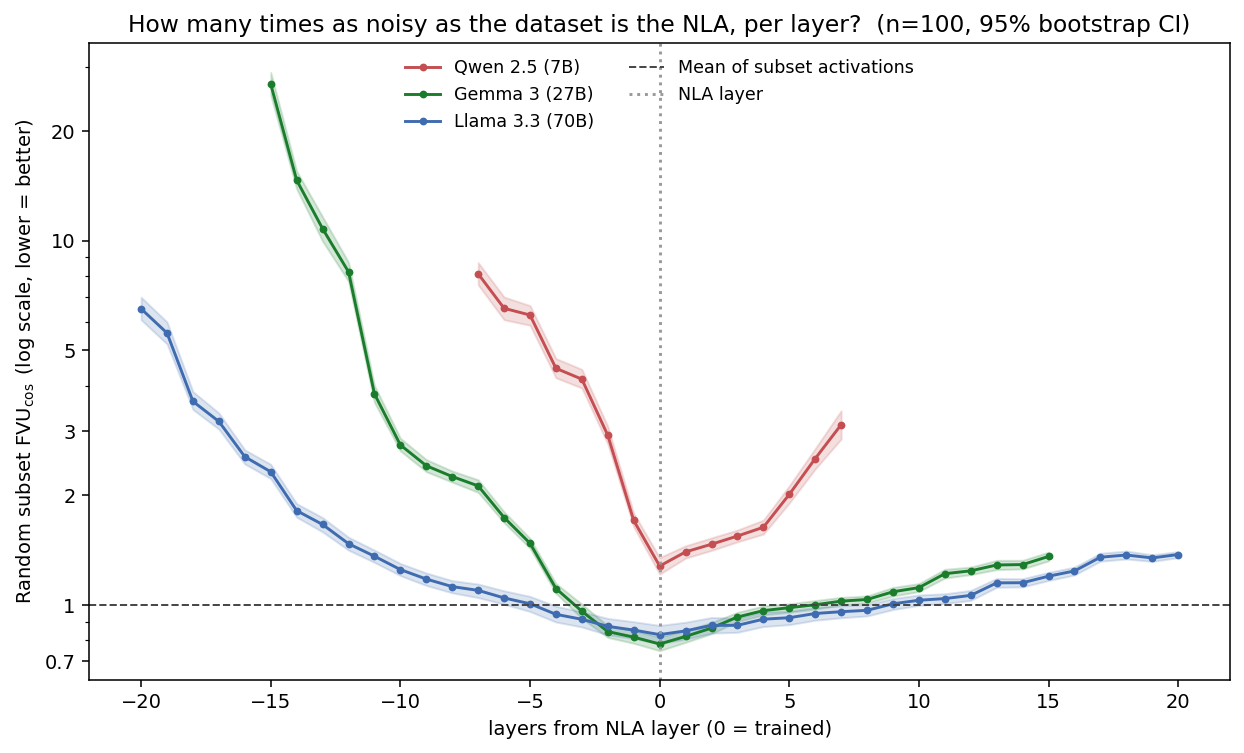
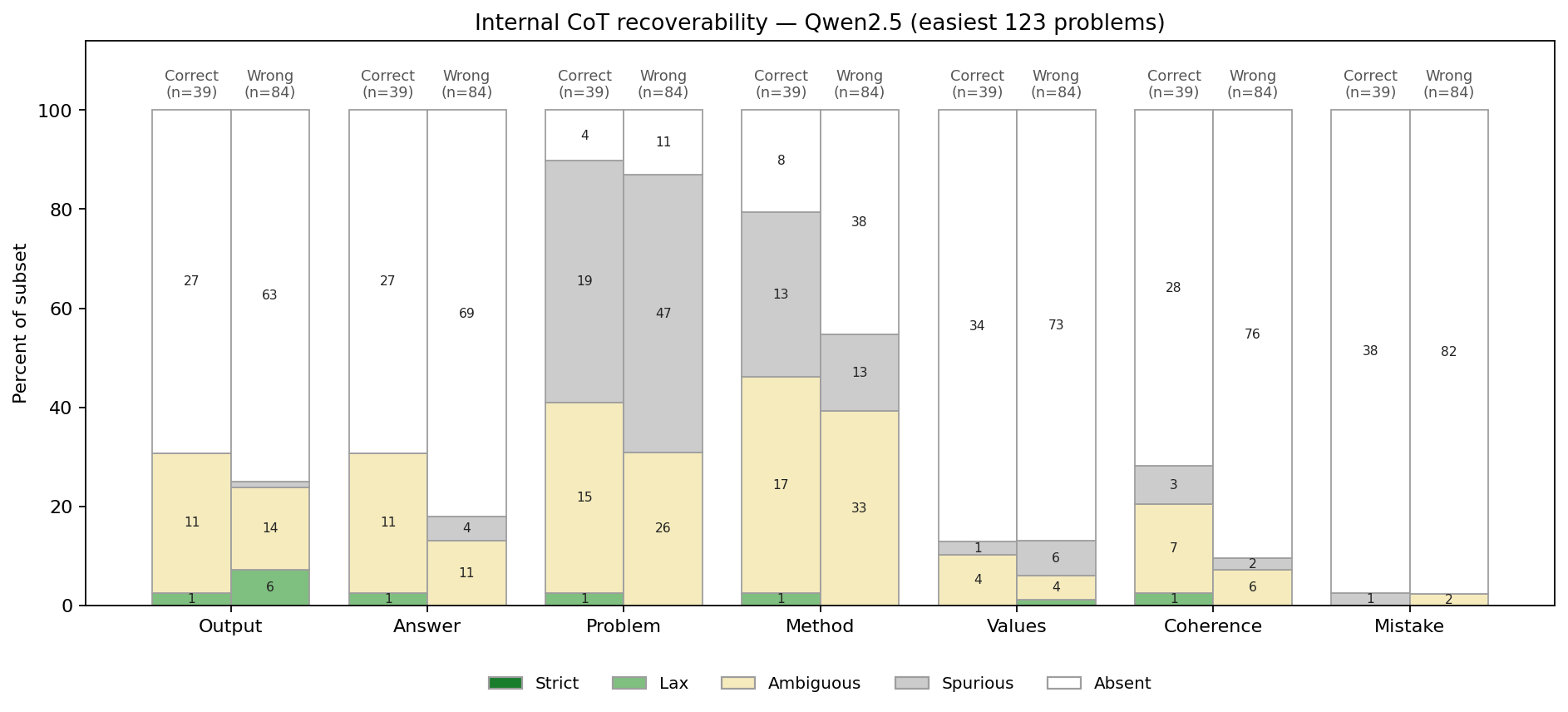
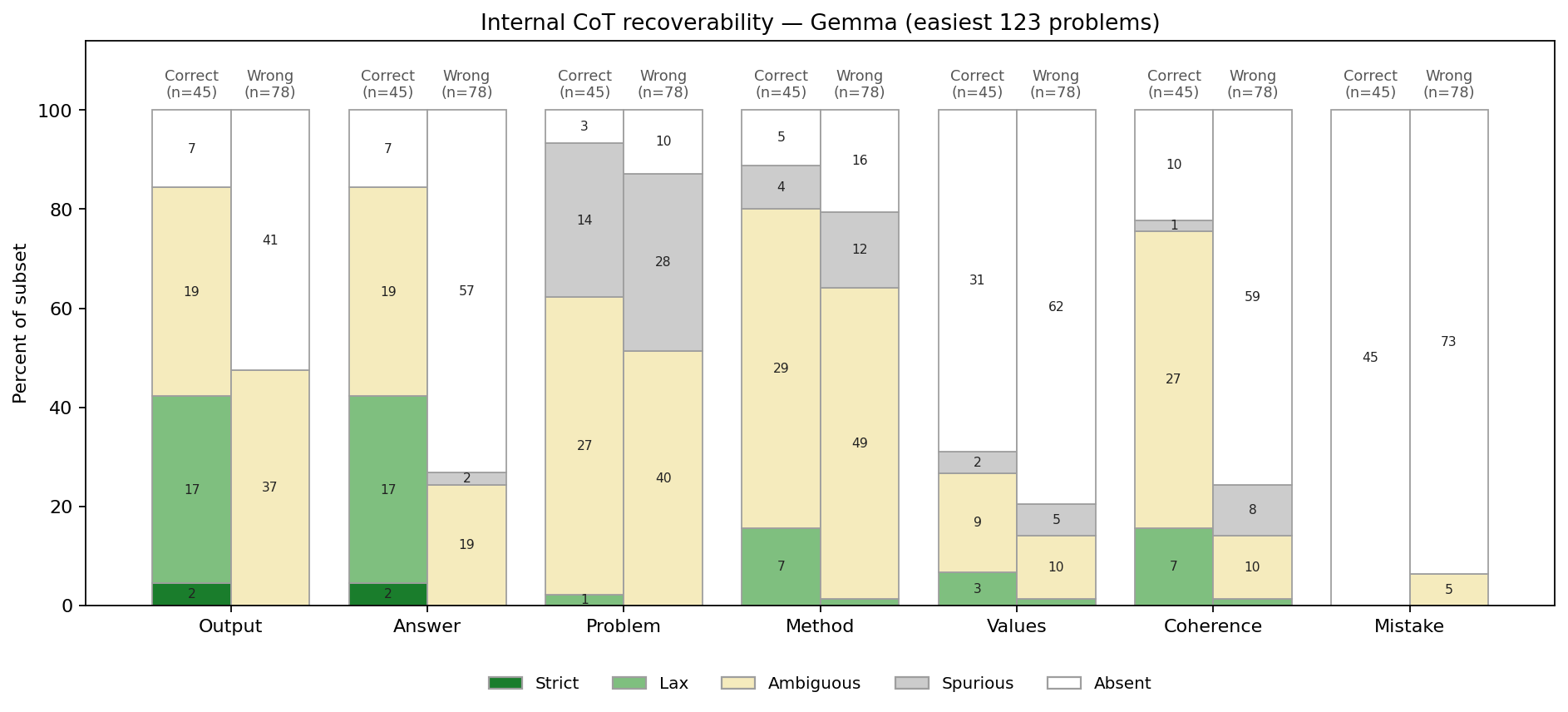
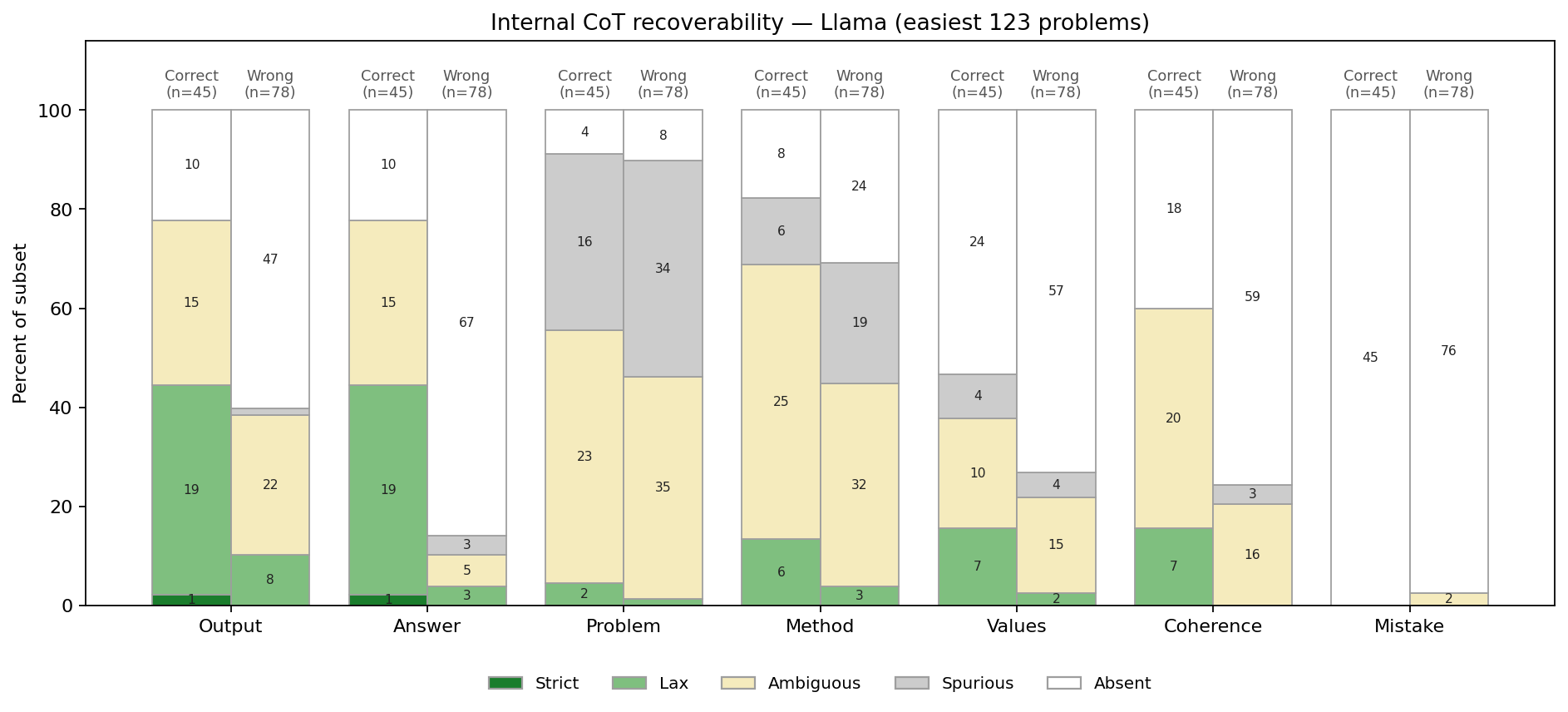
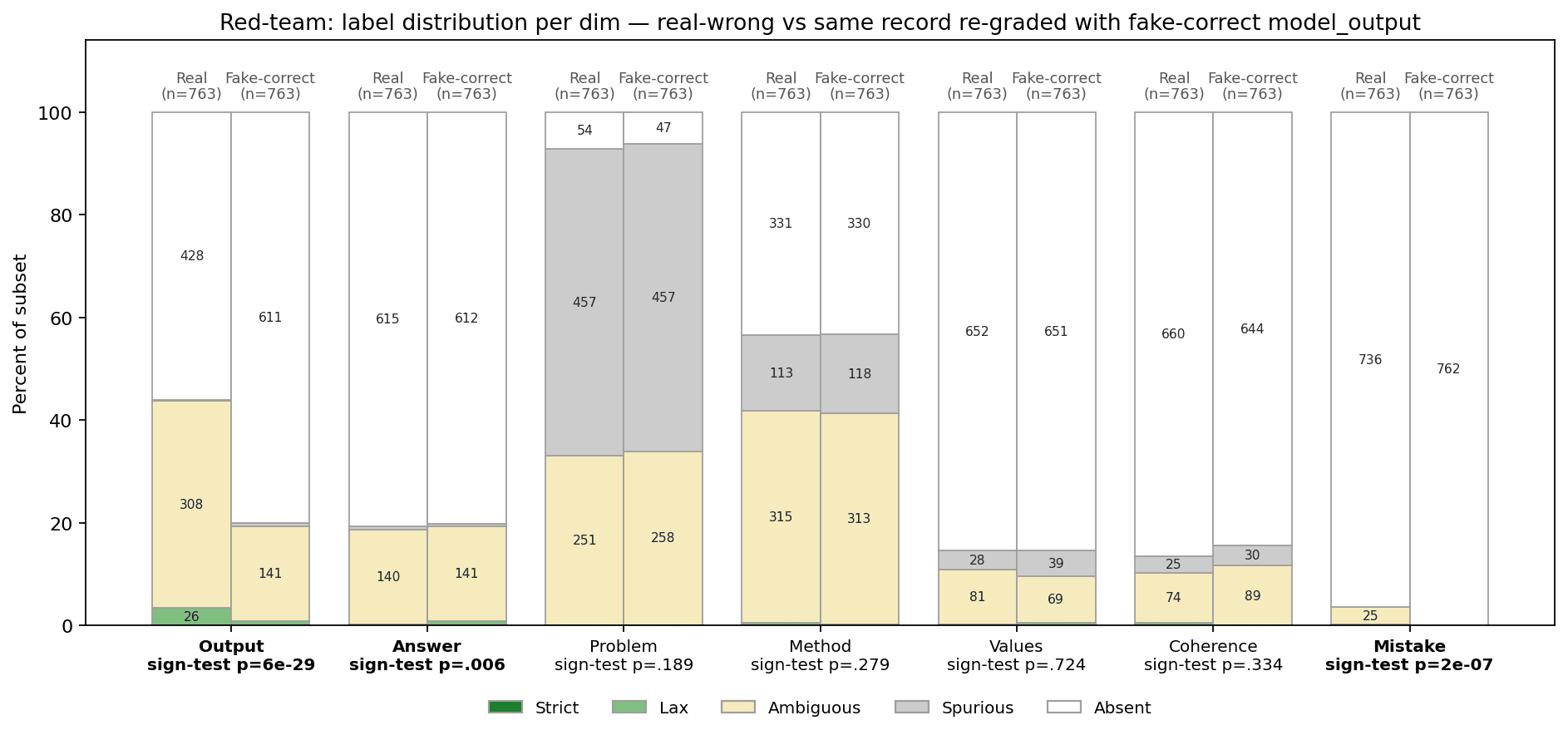
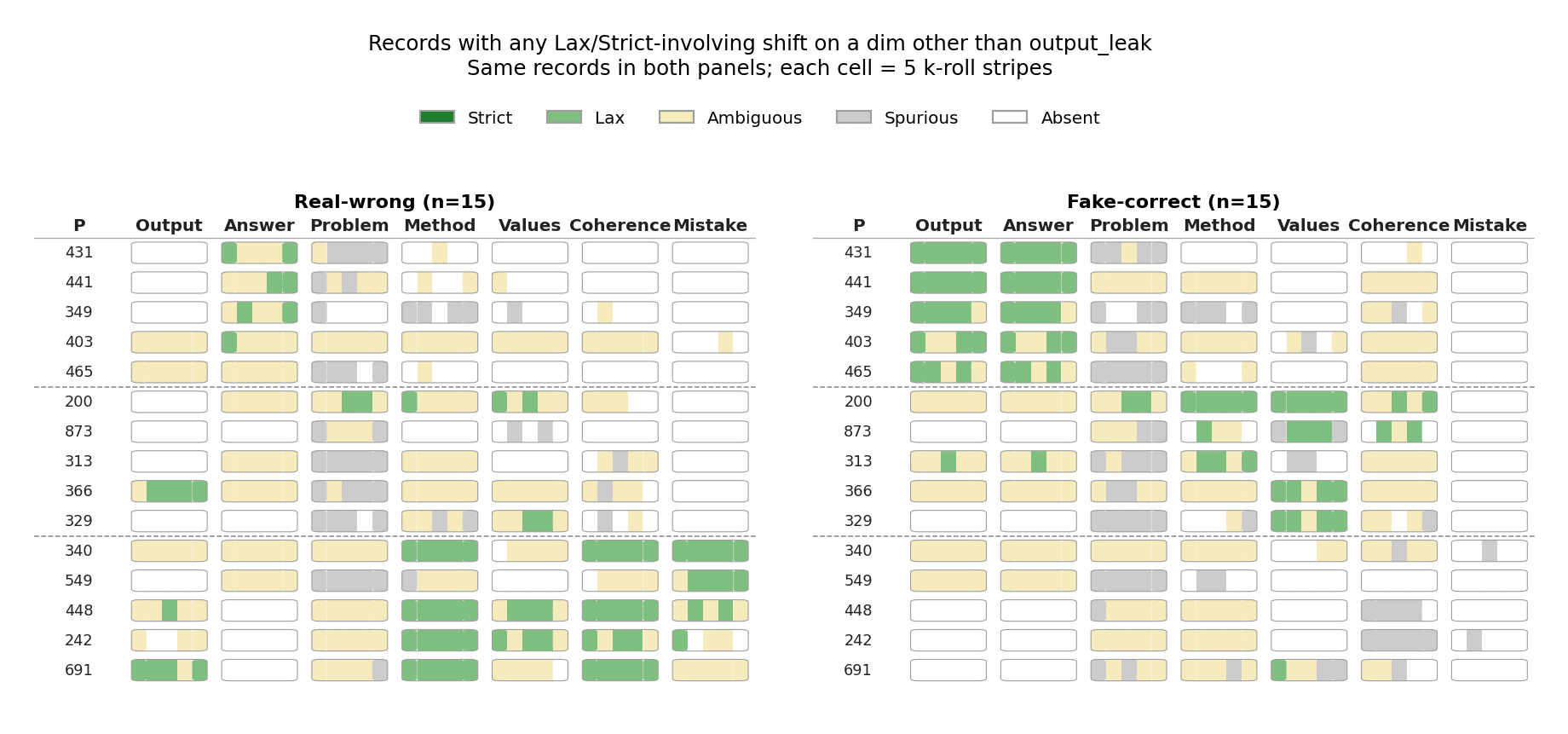
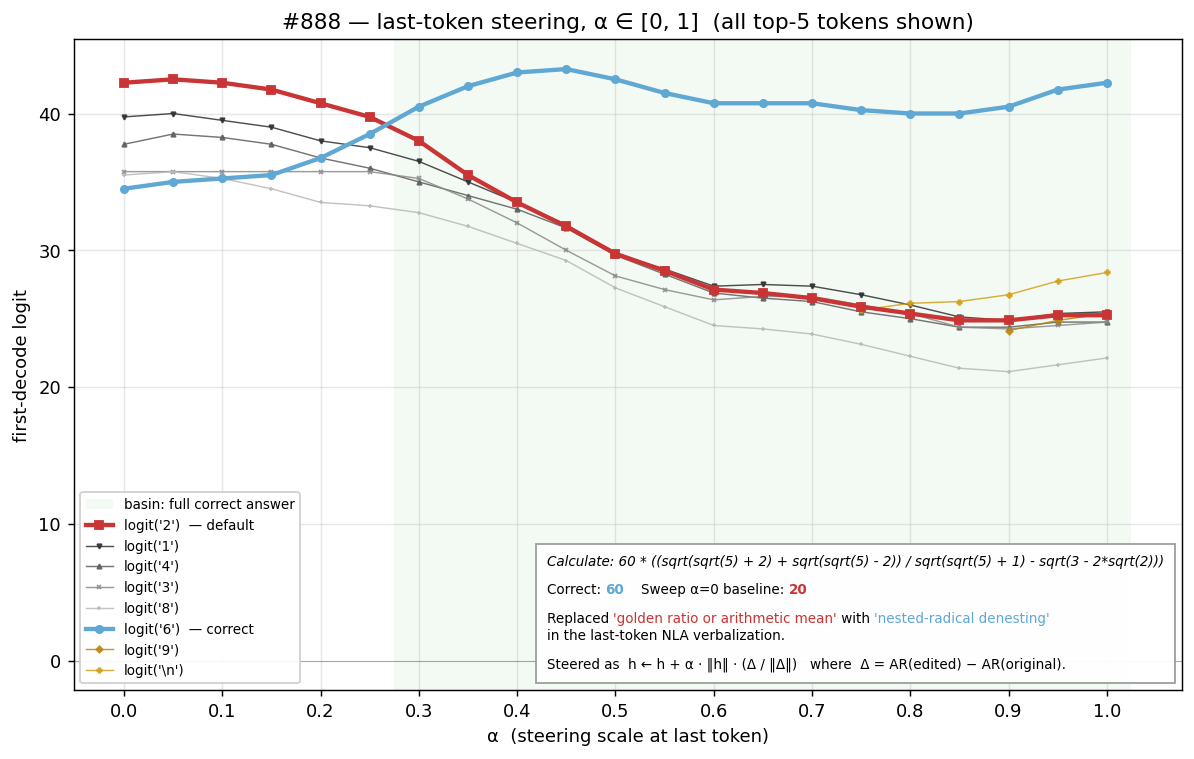
We introduce an evaluation for activation verbalizers: can they surface a target model's reasoning as it solves a math problem in a single forward pass? For open-weight NLAs, the answer seems to be: "possibly, but definitely not reliably".
Lots of important capabilities currently require AI models to reason "out loud" in a natural-language chain of thought, which means that we can monitor important parts of their thinking. It would be nice to have this same affordance for the reasoning that models do within a single forward pass, especially if the sophistication of that opaque reasoning increases to potentially dangerous levels.
Some interpretability tools might offer such an affordance. In particular, an activation verbalizer (AV) takes a residual stream activation and maps it to a natural-language verbalization. An AV is initialized from the target model and trained to generate verbalizations that an activation reconstructor (AR), also initialized from the target model, can accurately map back to the original activation. Together, an AV and its AR form a natural-language autoencoder (NLA). Importantly, AVs see only a single activation; they do not see the target model's prompt or next-token output, and – unlike activation oracles (AOs) – they are not asked any [...]
---
Outline:
(02:32) Takeaways
[... 43 more sections]
---
First published:
June 6th, 2026
Source:
https://www.lesswrong.com/posts/QQQAcKuWK6k98FivY/can-activation-verbalizers-surface-an-internal-chain-of-1
---
Narrated by TYPE III AUDIO.
---
Lots of important capabilities currently require AI models to reason "out loud" in a natural-language chain of thought, which means that we can monitor important parts of their thinking. It would be nice to have this same affordance for the reasoning that models do within a single forward pass, especially if the sophistication of that opaque reasoning increases to potentially dangerous levels.
Some interpretability tools might offer such an affordance. In particular, an activation verbalizer (AV) takes a residual stream activation and maps it to a natural-language verbalization. An AV is initialized from the target model and trained to generate verbalizations that an activation reconstructor (AR), also initialized from the target model, can accurately map back to the original activation. Together, an AV and its AR form a natural-language autoencoder (NLA). Importantly, AVs see only a single activation; they do not see the target model's prompt or next-token output, and – unlike activation oracles (AOs) – they are not asked any [...]
---
Outline:
(02:32) Takeaways
[... 43 more sections]
---
First published:
June 6th, 2026
Source:
https://www.lesswrong.com/posts/QQQAcKuWK6k98FivY/can-activation-verbalizers-surface-an-internal-chain-of-1
---
Narrated by TYPE III AUDIO.
---
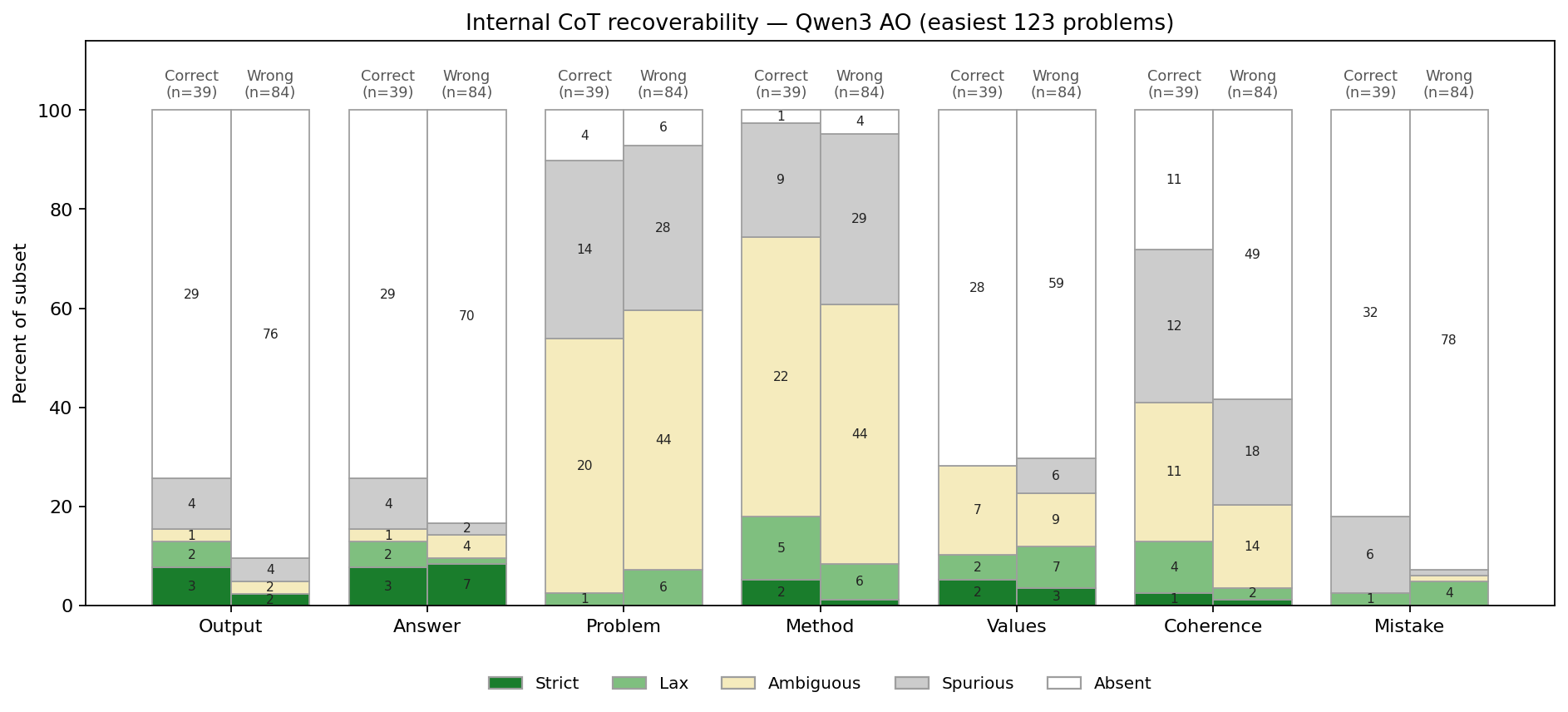
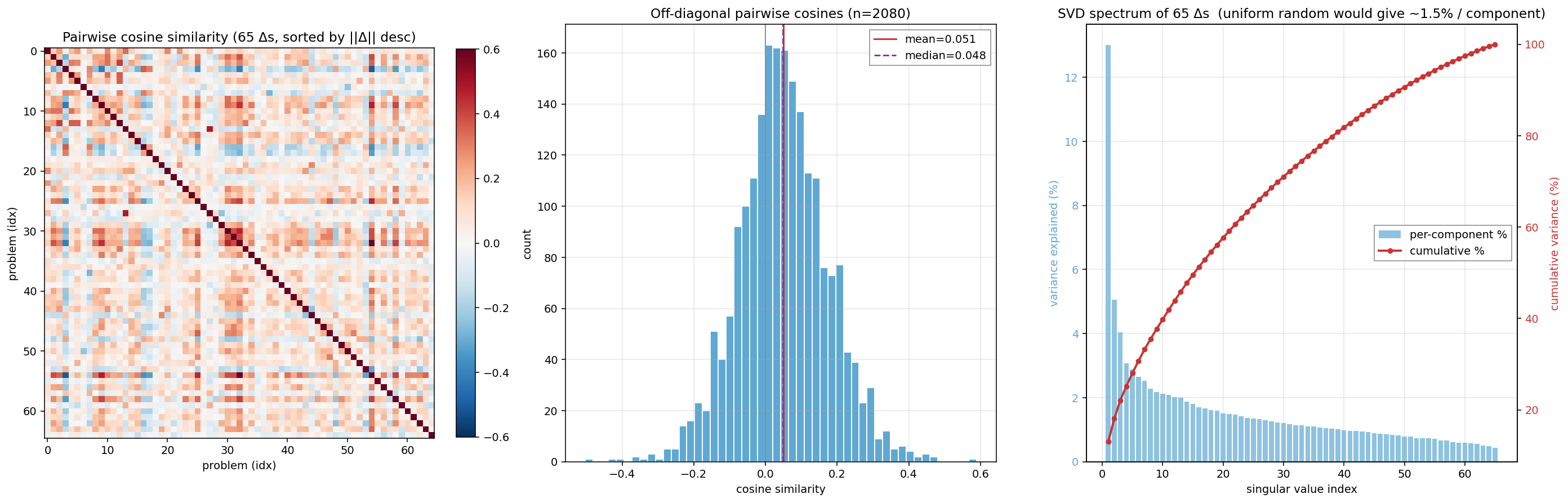
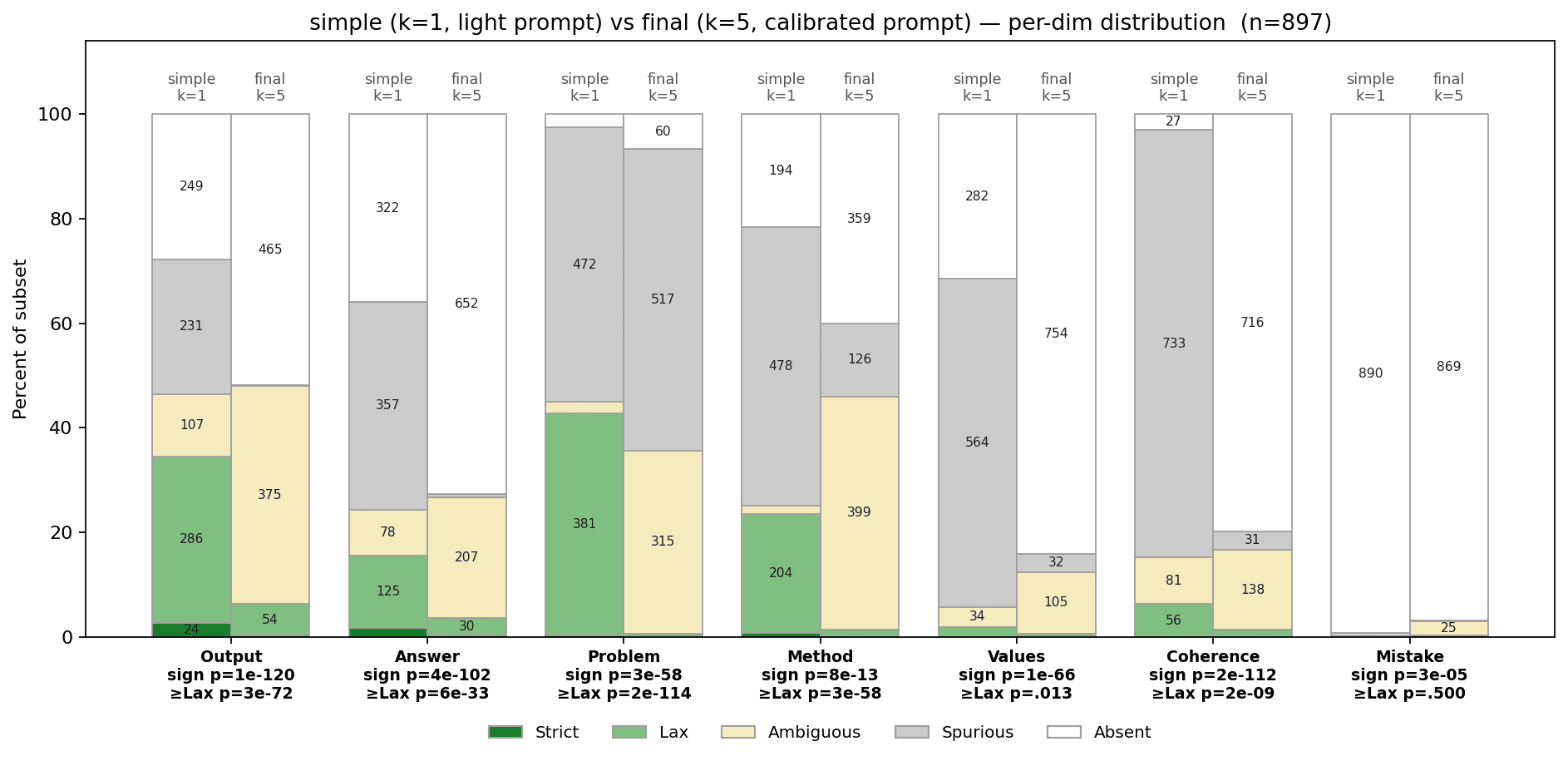
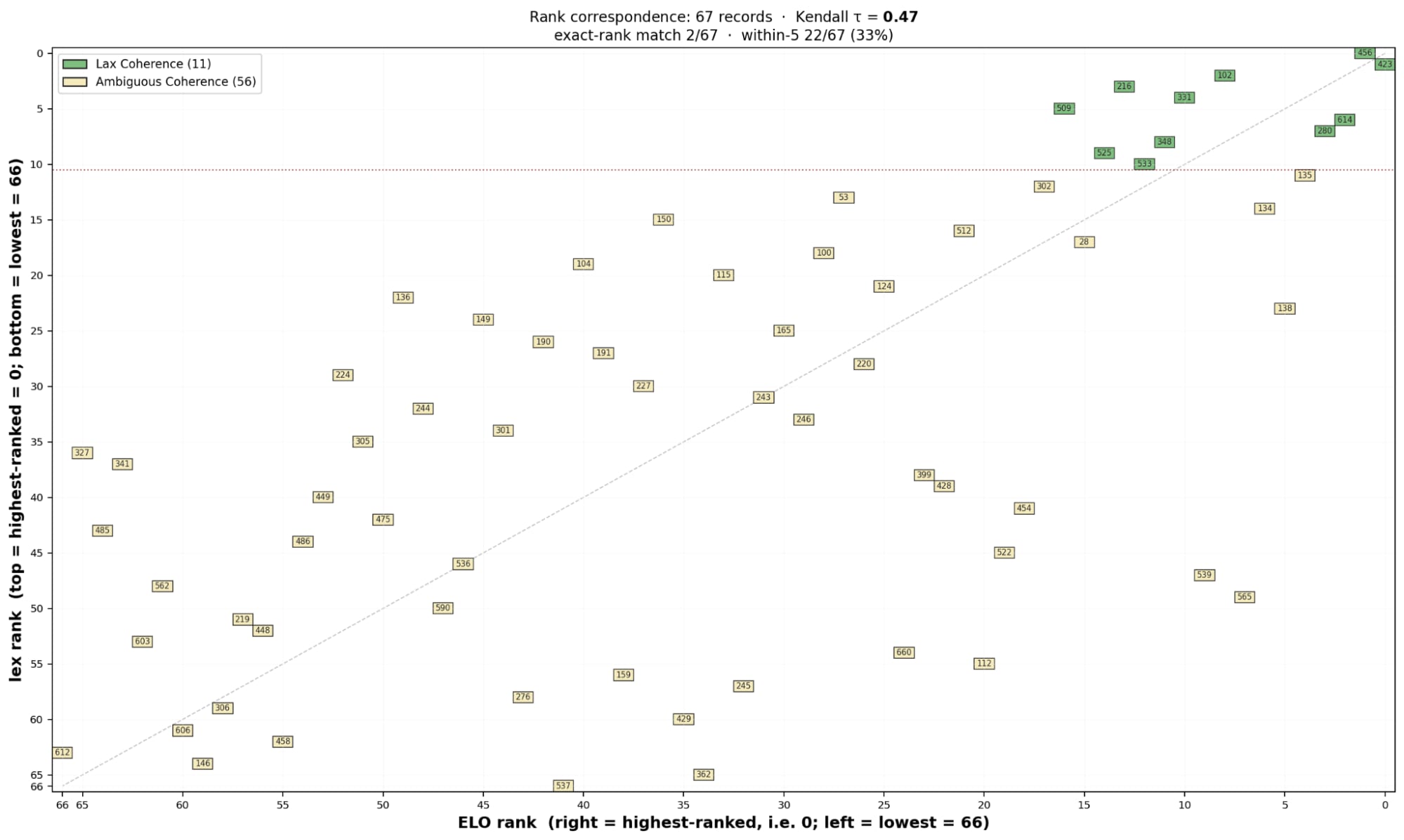
Images from the article: