
Enough About AI
A podcast that brings you enough about the key tech topic of our time for you to feel a bit more confident and informed. Dónal Mulligan, a media and technology lecturer, and Ciarán O'Connor, a disinformation expert, help you explore and understand how AI is affecting our lives.
Enough About AI
Expansion, Economics, Erotica & Education.
Use Left/Right to seek, Home/End to jump to start or end. Hold shift to jump forward or backward.
Dónal and Ciarán return with more "Bubble Watch", reporting on the latest expansion in valuations, hype, and attempts to find new ways to commercialise AI. Among those potential avenues to income, they discuss emerging AI robots, OpenAI's decision to allow AI erotica for adults, and the push to get AI into education - as well as the associated concerns. This last quarterly update for 2025 draws together some themes that you've identified in your submitted comments and questions and tries to end on a little hope amid a lot of anxiety!
Topics in the episode
- The AI Bubble gets bubblier - OpenAI's quarterly loss reports, Sam Altman's angry interviews, and the beginnings of a withdrawal of money from key parts of the AI economy.
- AI hardware in the form of robots like the recent XPENG demo and renewed concerns about labour replacement and military applications.
- OpenAI's hope of monetising via erotica.
- AI disinformation in the Irish Presidential election, as well as related stories in the Netherlands and elsewhere
- The unsuitability of mainstream GenAI tools to educational contexts and recent research on their associated Cognitive Deficit in learning contexts
- Top-down vs Bottom-up reactions and responses to AI in our lives and work
Resources & Links
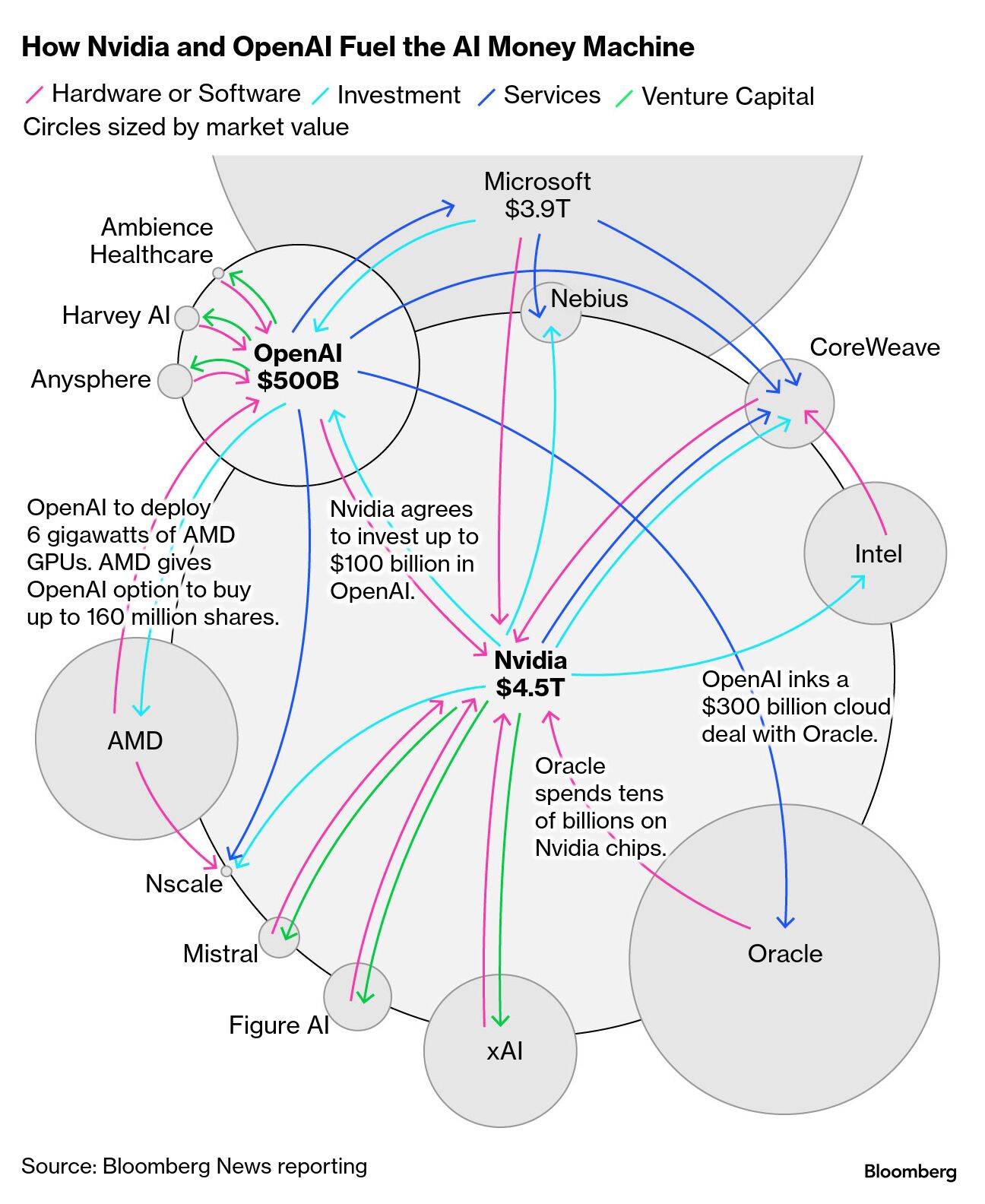
- The widely circulated images describing the circular investment within AI include this famous example from Bloomberg Reporting
- Recent reporting on the topic is widespread but includes these examples from WSJ, NYT, Ars Technica, Business Insider, etc., etc.
- MIT NANDA report on 95% of AI integration showing no return on investment
- MIT Media Lab's research on Cognitive Deficit and AI
- Reporting on the XPENG humanoid robot (Euronews)
- Reporting from Ciarán's colleagues at the Institute for Strategic Dialogue in a Digital Dispatch on Russian state content surfacing in Chatbot outputs
- More discussion of "LLM Grooming & Data Voids" in this Harvard Kennedy School paper.
- Fact Check reporting from TheJournal on AI videos in the Irish Presidential Election, including the infamous Catherine Connolly withdrawal fake video
- Reporting from Politico on AI Deepfakes in European Elections
You can get in touch with us - hello@enoughaboutai.com - where we'd love to hear your questions, comments or suggestions!

I'm Dónal Mulligan. And I'm Ciarán O'Connor. And you're listening to Enough About AI, a quarterly update on the increasingly complex ways that artificial intelligence is intersecting with our lives. On the last episode, we discussed the emerging AI bubble ChatGPT 5 and "non-woke" AI. We're still trying to figure out what that means. On this episode, we're going to look at an update on the companies and valuations of companies working within AI. We're going to talk about generative AI and the threats inherent to this in relation to misinformation and things like that. And we'll finish off with a discussion on the impact of AI on education. But first, I want to inhabit Wolf Blitzer and go to John King with a key news update on"Bubble Watch" here. Like CNN. We probably need a special theme tune just for"Bubble Watch" at this point. But yeah, I'm afraid for those hoping that things might have stabilised since last we spoke, the bubble is just getting bubblier! And at this point, uh, I think there's increasing concern from a wider array of people about what's beginning to happen. So, um, we're in a situation now where the valuations that we talked about just last quarter, so just a few months back, seem almost tame compared to what's going on. I think a lot of people will have recently seen, uh, quite a few different graphics that showed the circulation of money between some of the major players in this space, and very particularly from Nvidia, who we might talk about a little bit to some of the companies like OpenAI. Uh, I can run through some of the valuations or some of the key figures maybe, but I think the one that most concerns me at the moment is the very recent news from Microsoft, who are obviously a major investor in OpenAI, that it looks like OpenAI made a loss of about$11.5 Billion last quarter. So just one quarter of the year. Yeah.(My God.) So I think we're in a situation where, at the same time as there is promised investment on a really hitherto unprecedented scale - so there's talk about investments in the trillions from this company - the company itself is making a loss. And we talked - very poorly on my part - with, uh, a little bit of knowledge about economics last time, about how valuations are based on intended future income and about the relationship and ratio between those things and how very far off it was last time we spoke - that the companies involved here are being valued at enormous sums that have nothing to do with what their current income, or even their short term income is. And at this point, there isn't even income for OpenAI. It seems like it's making quite a substantial loss in the billions. And so that really is putting people a little more on edge perhaps, than even last time. It is. Yeah. The AI bubble fears are getting louder. All the while, AI infrastructure and demand is accelerating as the risks are growing - some of that demand. It's interesting that, uh, again, last time we we talked about the parallels between the dot com bubble and the current that we're in - and we talked about the fact that, you know, though that bubble came and had similar sorts of valuations going on and popped, there were some longer term implications for for how the internet happened to develop. So, we talked about the way in which infrastructure built during that period and funded from the huge amounts of money flowing around then did survive through that bubble and kind of became the basis of the fiber broadband that we depend on now, and built the services that appeared in the 2000s etc.. Em, there is a similar thing going on here - there is a huge amount of investment happening at the moment, and an interesting parallel that we can perhaps make again with the dot com is that during the dot com bubble, the company Cisco was one of the companies that were, you know, most valuable during that period. What does Cisco do? It is the company that makes a lot of data centres and related to that earlier stage of the internet. So we can see, I think, the parallel with Nvidia in our current moment. Nvidia are the ones that I mean, they're not the only ones, but are the major provider of the chips required for these kind of systems. And so they are valued at extraordinarily large sums, I think. Is it a how many trillion are we past a five trillion valuation for Nvidia? Nvidia recently hit five trillion dollar valuation. So that is the highest valuation I think there has ever been for a company. So it has done so because of this connection of, uh, you know, building the infrastructure within this moment of of this so crudely, it's the person who sells shovels during the gold rush who makes the money in the long term. And Nvidia seems to be in that place, what Nvidia is doing and what many of those diagrams, some of which we'll put in the show notes are trying to illustrate, is the very labyrinthine process by which Nvidia is taking that actual and future projected, uh, value and circulating it to companies with promises from those companies that they will in the future by Nvidia chips. So you can see these kind of circles within circles. Again not great if you're talking about it being a bubble to have lots of bubble shaped things going on. But we can see that there's cyclical flows of money between, for example, Nvidia and OpenAI or Nvidia and xAI. And in these cases, Nvidia is making these investments of real and theoretical fund. And they're requiring that that money be used to pay Nvidia back buying chips. So there's a lot of kind of passing money between similar related organisations. It's a lot of money for shovels. It is. Yes. Yeah. And it's a source of worry. This is divided people. There are quite a few, uh, who, uh, you know, point to the fact uh, it's reasonable in certain economic situations for us to have imbalances of funding or for, you know, a company to money to its employees who might in turn buy products from that company. And that is true writ large across an entire economy. But it becomes really problematic when it's very focused on a small, narrow group of companies, because it only takes one or two of those to begin to slip for the entire thing to come down. I mean, that's the basis of a bubble, as we're probably with already from housing or from the dotcom. And as this inflates, as more value goes in, as that huge increase in valuation isn't accompanied by evidence that there is money being made, or there's a way for people to get their money back. This the thinness of that bubble is is getting thinner, and it's further by the day. You touch upon a piece I was reading during the week by the that broke down, the discussion around the AI bubble into the good, the bad, and the ugly. The good was a continuous boom, hoping that all of this works out and benefits humanity and eventually yields return on investment. Whilst the bad was a gentle burst market correction and recession, which I think is interesting to put as only a bad a bad burst. But interest rates would rise as a result. And then the ugly was crashing and burning, and the question of what might happen to banks if they're caught up in AI companies defaulting on their that for things to use, for things to use to build data centres and that kind of thing as well. Should we read much into SoftBank recently, deciding to sell five point eight billion dollars worth of Nvidia stake? I mean, we don't need to because lots of other people are reading this for us, I think. So we've probably if you're not familiar with this, maybe it's to say a little bit about who SoftBank are and what their kind of role in this space is. Yeah, a Japanese bank and a mass investor of lots of technology companies. I think they were quite involved in Salesforce for a while, and they've been involved in Nvidia too. But as you say, yeah a large scale withdrawal of of their stake Nvidia. And so it's been seen I think by a lot of people within this space, as one of the early indicators of are people trying to pull back from this, so are the sort of people who are most in the know about where this value is, whether this is likely to pop at some point. Are they, you know, early canaries in the coal mine for, for this potential, you know, popping. And so it's not the only indicator that has happened recently that's begun to alarm people. So of course evaluations themselves. Of course, the news of that level of loss by OpenAI in terms of the, the quarterly, uh, figures recently, but also that recent interview with Sam Altman. So listeners might be aware that Altman, who has been one of the generators of of AI hype and is the the leader of OpenAI in but has become a sort of generic spokesperson for the the entire sector. Uh, he had a very defensive interview recently when he was about some of these kind of figures and valuations. Yeah. Speaking on a podcast, he was quite bullish. He said, "If you want to sell your shares, I'll find you a buyer" in response to the host's question and then carried on and said"Enough!" Yeah, yeah.(He's tired.) It was his his kind of the level of I mean, I presume there is a degree to which he's getting the same questions all the time, and maybe he's very upset to constantly be asking those questions. But I think they're pretty legitimate questions. And I think unfortunately, because he has positioned himself as this poster boy for the sector, it's really important that his attitude is something that's going to be watched and read into. And again, I think it's one of several factors that are to to cause some dismay amongst investors and therefore amongst everyone else who's dependent on this sector. Quite concerning, I think. Yeah. And at the same time we also see that, well, we saw initial comments and then a kind of pulling back of walking back of these comments where OpenAI were said to be seeking a federal backstop for new investments, which then forced their CFO and Altman subsequently to walk back those comments. Do you think do you think they are wishing to become too big to as the cliche goes? I am very worried about this. I think that there's a concerted effort by not just OpenAI, but I think by some of the large, highly valued AI companies in general to position themselves such that if it does fall apart, they will get bailed out in the same way. And I think, yeah, there was a lot of of anxiety about that phrasing that the CFO, the chief financial officer of OpenAI, made. and so mentioning words like backstop immediately puts people mind of, you know, things that are still feeling fairly fresh in terms of, of, uh, difficult political decisions and where money might go. And so it begins to set the scene that perhaps there's work behind the scenes, that this was a public slip up about something that perhaps is going on that we were less immediately familiar with. And I think that's a lot of speculation and reporting has on that in the recent days and weeks following that. And so I think all of this together does look like we have a precarity in terms of the valuation. We have a precarity in terms of the lack of commensurate money coming in. To balance this out. We have these other sort of indicators like that slightly interview or that a parent discussions of future bailouts things like that. So it does seem like the sector is trying to reassure itself and perhaps, you know, being involved with governments and trying to to negotiate potential bailouts in the future is part of that. But the numbers involved here are Astounding. And I think all of the bubble talk is not at all concerning when you factor in things like the study by MIT Nanda that found that ninety five percent of generative AI pilots deliver zero return on investment. They found that most enterprise AI tools don't retain feedback, adapt to workflows, or don't improve over time. And without those qualities they stole. Yeah, this is really interesting. I mean, I've been speaking at various AI events and and involved in kind of panels and things recently, and that particular study has certainly come up at pretty much single one. It's really it's interesting because the study is one of the first longitudinal studies. So it's over a period of time, it's looking at impact not as an immediate kind of hype moment of this seems like something we can put into lots of places within our company. But after a period of time when the investment is made, what was the return on that investment? And as you say, it's pretty bleak. It's ninety five percent. There is no return. This was, you know, wasted money to some extent in lots and lots of cases. I think it's important to say, because there's a lot of kind of against the study that's pointing out, you know, the fact that it happened at a slightly earlier stage, it's not it's not going to cover absolutely everything. It is an indicative study, as all scientific studies are. It's it's going to have a biased sample. It's going to be at a particular period of time. And so there will be, I'm sure, many more studies. It's going to to be the first of many. But because it was a fairly large, robust study that was, you know, one of the first to be published by an eminent like MIT, it's gotten a lot of attention, and the kind of two outcomes for it are that headline feature of the five percent that maybe this AI thing is more hype than we thought, and maybe there aren't places where it's going to make huge differences. But there are important things to say about where the five percent is working, I think, and I do want to acknowledge that the same study does show that this kind of technology has a very uneven application in terms of what it's making more efficient and more productive. And in spaces like software design in particular, so where coding is involved, I think it has been effective. And I think we can see that that, you know, the five percent are getting a lot out of it, while perhaps the ninety five percent, the larger, broader kind of parts of the economy that are trying to apply these technologies are having much less success. So as a consequence of bubble fears, AI companies are looking for new ways for their technology to be applied in, well, ever increasing numbers, let's say. We've seen OpenAI's Atlas browser, we've seen the development and release of Sora two. We've seen other companies. XPENG has released its humanoid iron robot, I believe, which is lifelike as well. Yes, really reassuring to name it iron. Also, it has a very strong Terminator vibe. Interestingly, they're calling it a gynoid rather than android robot because it's sort of feminine in shape. The XPENG robot is an interesting one because we talked previously about the emergence of AI as hardware, in addition to being software to kind of services that we might access online or via apps. And we said that that's probably going to be where the real money be made and mentioned before how OpenAI, for example, was working with Jonny Ive, the former Apple designer, to think hardware products that might use these. And so this is an extreme version of a hardware product using AI, but it's not a surprising one. We have robot stuff happening from OpenAI itself, from xAI, etc. the XPENG one I think received greater attention, firstly because it's a female looking robot, but also because the robot, I think had a bit more poise and elegance in terms of its ability to walk and move. Often they've been perhaps a little clunky, so I think it took people by surprise who might have been used to seeing some of the previous videos of the robots stumbling or having with steps, or I think recently there was a robot was providing ice cream to people as a sort of a public and it looked fine in a photograph. But when you watched a video of it, the speed with which it was doing it was really problematically slow. And you could see that people were were slightly impatient waiting for it. The XPENG demo, I think, was much more robust. It did seem to be a lot more responsive. And so I think that will be an interesting area because that, is going to, I think, awaken a lot of competition in that particular space. And again, for those people who have concerns about robots replacing humans in lots of areas of labor and work, uh, you know, we developed effective robots is really a place that's going because that is the application of what these humanoids may be working in large giant factories or those kinds of manual jobs. And I mean, I think, you know, the obvious source of funding for these companies who need these huge sources of funding is either at a enormous scale to replace human labor and therefore to make money that way, or to have huge, very, very expensive military contracts supplying robots for that space as well. And I mean, neither of these things are good things for the future of humanity, unless they are extremely well planned, unless they are regulated well, unless they are part of a democratic discussion that we all have, and none of that is going in the right direction, I'm afraid. It's really not. Um, and other areas where we're seeing AI companies move into it feels a little twenty seventeen, twenty eighteen where we're seeing AI companies pivot to video as well. OpenAI is preparing to launch a standalone app for video AI model Sora two. It will resemble TikTok, I believe, except that all of the content will be AI generated. Yeah, I've heard it referred to as the TikTok of slop, where it's basically just, uh, kind of, yeah, a video output. But, you know, with generated videos, it's interesting. It's already available. So it's I have not used it, but I've only read reporting on it and I've seen some examples, but I'm not signed up to it and I probably will avoid doing so, I'm afraid. But the idea of it was much like the GPT model itself was turned into something via making it a chatbot and creating ChatGPT and making it a public facing interface. I think they're trying to do the same thing with the video model they had. So Sora has been the AI video production model from OpenAI for a long time. There are other competing ones. There's Vo is a very high end one from Google, which is, I think probably at this point more capable and certainly more capable of making longer videos with synchronized, realistic audio in them, with lighting effects, with camera movements, these kinds of things that look more cinematic. I think the the leads in terms of that quality of video is with but with Sora, OpenAI had a tool that people were, I think, experimenting with making incidental short videos, and they thought, well, this is perhaps a similar situation to people loose on ChatGPT. So they're making a social network of sorts, but I think it's more to have people try something out to establish its to them. Interestingly, one of the ways they've chosen to do that, which I find a little bit problematic, is that they're encouraging to use their own likeness and the likeness of their friends within the videos. So they're asking people to make sort of deepfakes of a funny of your friend. I don't know, falling over or farting or whatever it might be. so, rather than making outlandish and cartoonish and video, part of its focus is to make realistic enough video involving real people who are identifiable. And that's problematic, I think, because we're verging into friendly deepfakes at that point. And friendly deepfakes are not that far away from unfriendly ones. And I think we're really seeing a problematic blurring of lines you yourself talked about in previous videos when it comes to where this might go in terms of election interference. We saw a little bit of that in Ireland. We did. Yeah. And some of the things you mentioned in the last few minutes about the the race to expand for these companies, the lack of regulation, impact on democracy, even down to the video you mentioned there, all of these things were present in some research that I carried out with the organization I worked for during the recent Irish presidential election, that in the last week of campaigning, a video appeared online showing Kathryn Connolly, the then frontrunner in the race, went on to win and is now the President of Ireland. But the video depicted her days out from the race, saying that she was announcing her withdrawal from the race. The election is now cancelled and Heather Humphreys, who was the Fine Gael candidate being installed as president by by default. I have to say this video was not just in an Irish context, but in all the work I've done in this area, probably the most advanced or sophisticated or just real looking. Um, video created with video, the watermark was there, shared on multiple platforms, and whilst the account that published these videos on social media had the term AI in the title, there was multiple scripts of that video, people probably being shared on WhatsApp devoid of the essential context that this wasn't real. We saw real RTE news reporters depicted as deep fakes as well. all of this just contributes towards further blurring of the between fact and fiction. Potential election interference. The non labeling of this content, which is a massive challenge in this area. The non labeling of this content by platforms, letting users know that it is um, that it is not real. And that was I suppose the the tip of the iceberg. We also saw so much slop during the election as well of of people claiming Catherine Connolly saying all sorts of wild things. Heather Humphrey was involved as well. And really it kind of shows how we're up against it so much of the large scale and the ease of access. And also we simply at this stage have no idea who made those videos. That's the really worrying thing, is that it's possible to create something with the sophistication that had. And I saw the same video, I had the same reaction to it. I think it is a combination of how I mean, it was not fully but it was good enough to certainly on a mobile phone that if you're looking at it in passing as part of a news field, it certainly would pass. It had real people represented. It looked like Connolly was speaking her, you know, the was better synched. Again, video is famous for doing this with with the mouth movements of the person. It featured real journalists, as you said, and looked like it had from the from RT news. And it's yeah, it's problematic because we we talked about this but we live at a time when our social media landscape is so fragmented that the idea that you can just label that in one place is slightly ludicrous. We need something that is capable of carrying across. And a lot of where I saw that video, I was seeing it embedded in other contexts, and I was clicking through to see where original was. It was sitting on YouTube in that case, and on YouTube, the name, the title that you could see if you saw it on YouTube did identify it as synthetic or fictional. It did mention that it was AI, and I think that's probably giving cover to some extent to YouTube to leave it up there because it is in their context, on their website, marked as it should be. But the problem, of course, is that very few of us see things only in their original content. Exactly as you say, things get clipped, things get reshared. Even embedding that video elsewhere removes some of that context. So putting it on a website, putting it into a newsfeed, etc.. And so I think unless this is more urgently looked at, I think we're going to move increasingly into a space where it just becomes impossible to discern what is real and what is not. And I mean, that is a pretty dire place for democracy at that stage, and not just Irish democracy too. Since we recorded our last podcast to the Netherlands, had a general election as well, and during the campaign there, two members of a political party there were found to be behind an anonymous Facebook page promoting deepfake images of their political arrivals ahead of what was a very tight election. And I think that the Dutch election was seen as one of the first elections in In Europe, in which this technology has become an integral part of election campaigns in various ways. And I think it's interesting to look back at, at some of the episodes in our first season where we discussed the impact or the speculation of AI on elections around the world, and the general consensus was, was that there was a lot of hype, but not much impact. I think we've moved down the line now, and I think we are seeing how normalized this technology is for what would become very ubiquitous, genuine ways of political campaigning, but also of the more deceptive and potentially harmful ways as well. And there's so many ramifications for platform accountability and how they respond. How should regulators, electoral commissions and different respond, but also at a general wider level for public opinion, for media literacy? And what tools can we provide people with because the barriers to entry to create this kind of content have have dropped completely. Yes they have. I'm very interested by a term that you mentioned, which was the grooming of AI models. I hadn't heard that term grooming, which is never a good term being applied in this context before. Can you say a little bit about that? Because I think it has interesting connections with this idea of trying to seize that information space that's emerging and changing because of AI. Yeah. So this is another way in which AI models are being used or misused to promote deceptive, misleading, potentially hostile let's say. Yeah. Some research carried out by my colleagues found that chatbots, which are underpinned by these systems, these llms that we talk so much about, are competing with traditional search engines as users preferred ways to search for information and in particular, news. Now, research has found that hostile states and other types of nefarious actors may be attempting to influence chatbot results. This has become known as LLM grooming by targeting essentially the data voids that are inherent in these in these large language models. So where searches provide few results from legitimate sources, and the tactic, I think allows risks allowing false or misleading reporting around sensitive or important geopolitical issues to to be shared online. And in one instance, we found that colleagues found that influence operations have used hundreds of websites to aggregate content from specific, often state sponsored media sources and publish millions of news articles per year, with the likely intention being to generate enough content to impact the output of chatbots that scrape the internet for data. So they're trying to train. They're trying to groom the source of content by which these LMS are pulling their data from. That's interesting because it plays into some of what we talked about before in terms of the the volume of information involved at the point of training and something we've mentioned previously, the fact that in the current architecture of these models, often what they will do is be trained up to a point, but then also be a genetically capable be agents that can go on the internet, get information, synthesize that and include that in the response. And of course, we would want that. If the model is useful to us, it needs to not have that old in the early days of ChatGPT of having the knowledge stopping point and things being true only until a particular date in twenty twenty three or whatever it might have been. we expect these tools that we're using to be able to immediately go find things on the web. And of course, if they're doing that, part of what they're doing trying to encounter as much information on certain topics as synthesize patterns across that information. And exactly as you say, if someone has nefariously gone out to create lots and lots of independent reinforcement of the themes or issues or talking points in different places. That is slightly poisoning the data set to a degree. I mean, as we talk about this, I can't help but think back to when we started making these podcasts, and it's been a while now. It was last year. Even at that stage, we were still in that period. I think of looking at the initial intention around the creation of AI systems, and particularly the push for artificial general intelligence AGI, which we talked about. And in its first context, OpenAI was set up as this non-profit company. We talked about its, uh, the people contributing to it, the kind of mission it had, but it very much was, was positioning itself, much like Google did in its early days when it had the motto of don't be evil to be as something for the good of humanity, that it was about not generating profit. It was about creating something that was going to uplift society. There was a lot of talk, and we mentioned it in our early about things like universal basic income, that the creation of something that would, uh, you know, alleviate terrible work that nobody wants to do would create a situation where we need to think about what our future without work, like we have at today, might be. And it was a little bit more hopeful, at least on that side. now here we are in the situation where, you know, OpenAI is a for profit company at this point. The amounts of money are extraordinary, the losses are extraordinary. The impacts of it, such as it is at the moment and such as it to be, as it seems to develop in these various ways, is very negative in many ways. And, you know, we're not seeing the huge productivity gains we have. That ninety five percent study we're not seeing is bolstering society. In fact, the opposite with this kind of fragmentation and we haven't mentioned before, but I wanted to is OpenAI's move towards erotica, which really surprised me. Baffling, yeah. OpenAI have decided that they want to loosen up some of the guardrails that they have in place for older users, so that they can specifically use OpenAI products to generate synthesized porn effectively, so that they can use the tools like ChatGPT and the video generators to make adult content. And this is really questionable from a company that's, you know, had such a noble intent early on, but it is very tied, I think, to this need urgently for them to make money. And so I think they see a gap. There's always money to be made I guess, in, in the porn industry. And so I think there's, there's probably, you know, amongst the things that they're trying to do or these other forays into lots of areas, I think there's a desperation perhaps to make that balance positive, but it doesn't really fill me with hope about their goals that they might still have for the future humanity when this is where they're going now. No incredible things are happening on the internet in all sorts of weird and maybe not so wonderful ways. Um, we've seen the high intentions of of AI companies, of large language models, but we're also now beginning to see the impact, the especially cognitive impact of a reliance or an overreliance on these on these tools. And I know this is something close to your interest as an educator. A recent MIT Media Lab study and the, the, the topic of or the results showing kind of cognitive diminishment, is that right? Yeah. This is something I'm very worried about. The fact that one of the obvious income streams, apart from apart from, you know, the pornography, apart from these very many places that AI might take itself is to insert itself into education. If you're a large company who needs billions and billions of income, one of the ways you could potentially do that is to make yourself the tool of choice at various stages in the formal education process, in company or in countries, because the countries might then enter into billion dollar or billion euro contracts with you to supply educational tools for their primary or their secondary school. And I think this is really problematic if those tools are unproven. There is a very strong push currently from a lot of different companies. Not alone, OpenAI by any means to enter that space of education, and there is not good evidence thus far that the tools are right or helpful for that. And in fact, the particular study that you mentioned shows exactly the opposite. MIT Media Lab is a long established section of MIT that looks at technology and media. So I'm very interested in it. Given that my own area and Media Lab produced a report recently I Think Your Brain on ChatGPT, which was looking at exactly what you mentioned, looking at cognition. And so we previously talked on the podcast about the fact that there is a measurable Google effect. We remember things more poorly than we did prior to Google. We have problems where our reliance for navigation is impeded by the fact that we use Google Maps and other map apps all the time. We know that technology can take the place of certain kinds of and we speculated when we talked about this a few months back that increasingly, our reliance on AI might strip us of much more fundamental forms of thinking and and ability to use our cognition. This particular study, it's a small scale one, so it will be replicated, I expect several times. But like the other MIT Nanda study, this MIT Media Lab study is also longitudinal. It takes place over a period of time. It lets people use different tools, and specifically in this case, it asks people to use, uh, no technology at all. Basically, the standard read stuff from a book to write essays allowed them to use standard search tools like Google Search, but without the AI components and tools like ChatGPT. So Llms. And so these three strands, these people were asked to write, uh, you know, academic essays essentially on different topics where they had to learn about the topic and then synthesize that information and put it together in an essay. So understand it sufficiently well that they could describe it. And they attached, uh, little probes to those people's heads so they could measure their brain activity. So they very directly measured cognition. So what is the amount of brain activity, the cognitive burden people have when they're trying to synthesize information in these ways. And they found that it is lower if you're using Llms you are using your brain less if you are losing using LMS, and more so the more you use them. So over time, as people relied on them more and more, the faster they did the task. So the less time they were spending maybe interrogating the answers, they were perhaps copying and pasting the first thing that came out. But the less cognitive burden they had to, they were not thinking as much about it. And an interesting part of the study was that late in the study, they had people swap. So if you were someone who all along had used the LM like to assist you, that was taken away from you and you now had to work with actors. And they found that that caused what they described as a cognitive deficit. The people who had relied on it for a long period now greatly struggled, compared with their peers, to regain the sort of lost knowledge. Essentially what we're seeing over time, there was opportunities to learn that that person might have had, by engaging their own brain in the information they're were lost. They were exactly as we unfortunately were talking about those months ago. They were handing that cognition, that opportunity to learn off to the AI. And this is diabolically worrying to me, because if this is something that we introduce intentionally hoping to be into our schooling, as I mean, the Irish government has already introduced AI into the Leaving Cert, our kind of end of secondary education. But if this creeps into earlier moments of education, there's a very real likelihood, I think, that that sort of outsourcing of cognition will leave people with an enormous cognitive deficit, that at the end of their schooling, and as they try and move forward with their their lives, they will be just less able to think they will find it more difficult, and they will be less able to do the sort of things that we take for granted in terms of how we have learned as adults to synthesize information. The comparison is often made to the early years of social media with the development of AI, and that let's not make the same mistakes again. And I think we're not making the same mistakes. We're going even further. We are with evidence like this. Yeah, I'm terribly worried about this because I often feel I have colleagues in the TCU School of Communications who have looked at cyberbullying. Who have looked at social media disinformation. You and your colleagues have done the same thing. We can tell now just how dire some of what happened with social media was. It took us until now to really reflect on it and see what this did to young women and their opinion of their bodies, what this did to groups, and polarization and the political landscape, what it's doing for the far right, the the degree of negative outcomes that we're able to now, with hindsight, look back on should really immediately be wringing every possible alarm bell that we take things a bit more slowly, but we're not. And part of it relates to the very first podcast that we had where we talked about this absolute fear of missing out, that if we're not going in all guns blazing into the situation and sticking AI into as many things as possible, we are not being innovative in the right ways, and I'm afraid that I'm afraid that I think that has seized quite a few governments, Ireland's, and that we are very uncritically trying to adopt these technologies. And I hope that if parents are listening to this, if people who have, you know, friends who are teachers or are teachers themselves are listening to this. It will take a bottom up kind of reaction to this, to, to, to try and, and I think mobilize people to take this a bit more seriously. And I would be very worried about us uncritically beginning to adopt this in education, given what we're seeing and things like that. MIT study. Yeah, I think we've covered a lot of ground on this year's season. And I think given the culmination of this year, it would be helpful to end on a positive note, a hopeful note. Those are getting harder to find. I'm worried that that's the case, but can you tell me some more about those bottom up solutions that you've thought about? That is actually yes. I will say that that is where I'm finding the glimmers of hope that I do occasionally find these days. Because, as I say, we've talked often about p doom and how we feel about the doom of humanity. But at a more local level, I do feel that one of the encroaching about this, one of the most, uh, kind of pervasive sources of despair for me and for people I talk to in this, is that it feels inevitable that this is going to come in and displace more and more without any control, without any way for us to react or do anything. A lot of people are waiting for a solution to come, hoping that will appear. Hoping that in their own particular situation, in my case in academia, there's often a lot of sort of institutional paralysis while we wait and hope that some other university might come up with a good policy, that will be the one that we can all adopt and and hopefully that will fix things. And those are top down solutions we're hoping for to use the the business term for it, that something comes and from the top is a kind of generic response that can regulate or can, you know, manage things for us in some way. But I think everywhere where I've seen something useful, it has come the other way. It's bottom up. It's about people saying, I recognize that this is encroaching on Myspace, that I know something about. And I am able to then say, here's what I think we should or shouldn't do. Here are the tools that are useful, and there certainly are useful tools. I really want to say that although I'm saying terribly negative things about some aspects of AI, there are tremendously positive things. Also, AI is a very, very useful force in terms of certain kinds of productivity. I use it, I use a variety of different tools in my work, and know that students do, and I know that there's plagiarism as of that. But there are also excellent uses as part of that, too. And so I don't want to denigrate it at all. But I do want to say that where I'm seeing useful response, it's that people are being thoughtful about what it means to them and are making local policies for their particular area, or thinking about how they can best use it and share that sort of practice. And so I hope to see more of that. I hope there's more collaboration across institutions and sectors and countries, but I would urge people, if this is something that you feel strongly about, you should get involved in it. It's something that you can, if you're a critical person, about this might affect your area. If you're beginning to think about the ways in which this could be negative, then it's important to start working with others. It's important to start thinking about how it might affect you and your work and your colleagues. Yeah, another hat that I wear from time to time is in providing media literacy workshops to people who maybe have some knowledge, maybe not so much knowledge of navigating social media. And it's quite similar to this, really. It's often about presenting some of the risks, some of the harms, but also very much acknowledging the potential positives and all the good things about social media. But the most impactful workshops that I've been involved in or I'm aware of are at that local level. They're in libraries, they're in schools, they're in real conversations. And it sounds as though this is a similar approach. This is a way to go to provide that antidote. Yeah, I think it feels harder in this case because it's an often unknowable technology. In a lot of ways it feels magical and strange, and it feels pervasive and scary. And, you know, it's something that's more intimidating, perhaps, than social media now is to us because we feel we know it better and it's a bit more analysed and we're a little bit jaded with it. We have seen some of the negatives along with the positives, and I think we're able to view it a lot more critically, perhaps, than we are with AI, which seems to be rapidly, constantly changing, encroaching in new spaces in new ways. Now it's a robot. Now it's a different way of working. Now it's going to take our jobs away. All of these things seem to be coming at us and being able to look at where we can positively use it, and where we want to reject it. It's perfectly reasonable for us to say, this is not something I to have encroaching on the primary school classroom, and are the reasons for that. And here's how I might get involved. This is something that I can see working in this area of my life, not this other one. I think it's important for people to feel that they have agency themselves. We talk about AI agency a little bit too much and perhaps human not enough. But it is important to begin to have those conversations. And I think it's really vital for people to acknowledge where it's working, but acknowledge where it's not as well. And again, we previously mentioned this idea that Sam Altman would like us to think of AI as a PhD level intelligence in every area. And we talked last time about the fact that it feels like that only in the areas you were less familiar with. And of course, everyone, when they start using it, sees these making mistakes, sees where they're not useful or not or certainly from my point of view, not especially a good tool for education in most of their contexts. And so I think it's about sharing that critical view you have, because perhaps someone else doesn't have that same expertise as you or that same familiarity with a tool. So it's something we need to start talking about a lot more. But it's something that I think once we start doing that, we're much better able to feel that we can make a response that's useful. Well, that's a good, positive, I think, hopeful way to leave things for today and to leave things for this season of enough about AI, we want to say thank you to all of those who sent in questions. It really helped inform and shape today's discussion, and we look forward to receiving more questions when we return in the year with a new season of enough about AI. Thank you very much for listening. Thanks also to the people who have shared the podcast, or who've left us a review on Apple Podcasts, on Spotify, or anywhere else. If you're a listener and you haven't done that, please consider doing so because it helps other people to find it as well. Thanks.


{kind=link}